In this day and age, it’s almost impossible to hear about new software or tech that doesn’t mention at least one buzzword around Artificial Intelligence and Machine Learning. From optimised charging on your iPhone to the fully autonomous autopilot in Teslas, it’s quite apparent that AI isn’t really Sci-Fi anymore and is rather quite a large part of our everyday lives, whether we notice it or not.
Artificial Intelligence has taken huge steps in the mobile space in recent years, as chipsets get faster and more efficient, AI becomes more prevalent in the everyday software we use, therefore it’s almost a no-brainer to try and incorporate it into a use case for your app. Core ML is Apple’s approach to bringing the awesome power of ML to you, the developer, in a concise and intuitive framework and will be the focus of this article.
There’s virtually no limit on what you can use ML for, but for the sake of simplicity (and the fact this is a popular use case) we will be exploring how to create an image classifier and build it straight into your app. Let’s get started!
ML? AI? What is it anyway?
The background might be boring and you might want to jump straight into the code, but it is encouraged that you to give it a read for a very basic overview that may help with some concepts down the line.
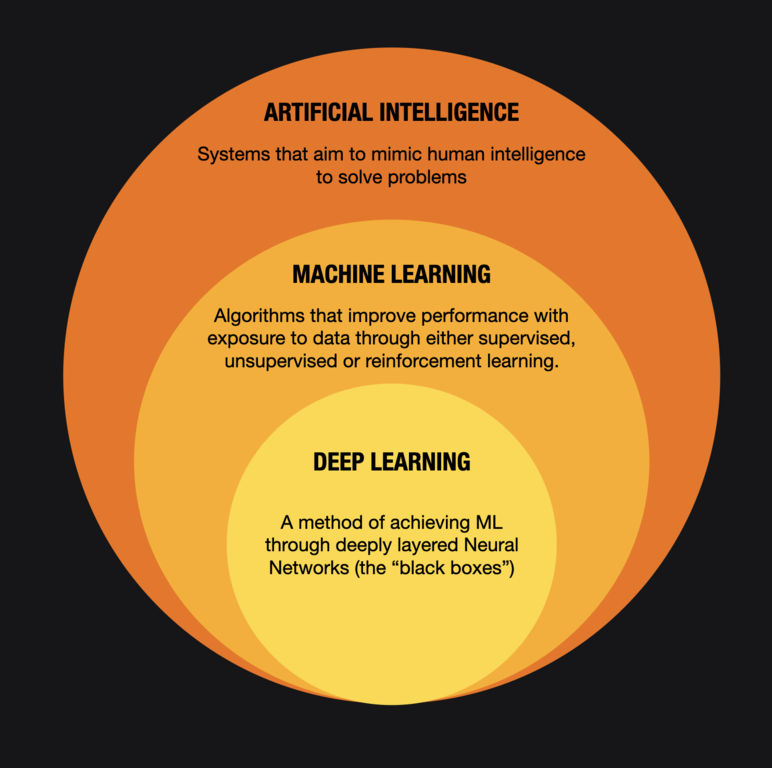
AI and ML are usually interchanged but there is a significant distinction, Artificial Intelligence is a broader umbrella term used to define all intelligent systems, while Machine Learning is a specific subset of AI that is focussed on getting machines to learn from input data, without being explicitly programmed (This can be done in multiple ways: Neural Networks (Deep Learning), genetic algorithms, particle swarms etc.) but all of those are irrelevant in the scope of this tutorial, all you need to know is that Machine Learning involves taking input data, feeding it into some transformational function (eg. a Neural Network) and receiving an output that describes the input to a certain accuracy.
Think of it as a black box that takes in the data we want to classify and gives us its best prediction of what it was given. The way we train this “black box” is what will determine the accuracy of our results, but we’ll get to the training of our model later on.
Creating your first image classifying app
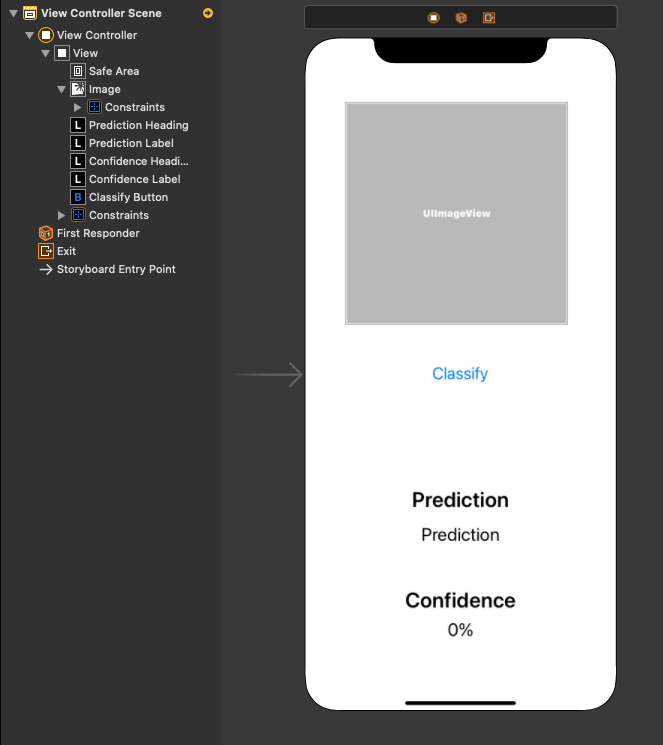
In order to continue with this tutorial you’ll need a very basic understanding of UIKit and storyboards. To keep this tutorial simple and not detract from the main focus, we’re going to use a very basic UI setup in order to display our input image, Button for triggering our prediction and labels to display what our model predicted and the confidence it has on that prediction.
Head over to Xcode and create a new project (selecting single view app and Storyboards as your UI Interface) and setup your main view controller to look something like the image below:
Drag any 224x224 image into your projects .xcassets group and use it as the default image in the UIImageView you set up above. We’ll get to why the image needs to be 224x224 in the next section.
Importing the model and passing the image through it
Now onto the interesting part of our app: importing our ML model and using it to create predictions. The machine learning model is the “black box” that takes in our image as input and gives us a prediction label and confidence as output. There are many models that we could use that are mainly deeply layered convolutional neural networks. A neural network is a mathematical abstraction of the human brain that aims to mimic the learning process and exceptional pattern-recognition that human brains possesses. They do this by simulating the brains huge network of neurons and synapses with multiple layers of nodes (neurons) and connections (synapses). These nodes take in some input signal, use an activation function, bias and weight to transform the signal in some manner and pass it to the next node which repeats the process until the signal is passed through the entire network. The output is then compared to the expected output and any errors are passed backwards through the network in a process called back propagation to adjust the neural network's biases and weights in order to minimise the network's error. This process of adjusting these values is called training. A model trained on lots of quality training data will usually produce a very accurate model, therefore it's very important any model you train receives the best training data possible.
Some models are trained for more general objects, while some are trained for specific domains, Apple provides a few popular models at https://developer.apple.com/machine-learning/models/ that you can download and drag straight into your Xcode project. For our project, we’re going to use ResNet50, a 50-layered convolutional neural network that is aimed at predicting dominant objects in an image over multiple domains.
Once downloaded, drag the .mlmodel into your project and click on the file to view the details of your model. Head over to the predictions tab, this is where you’ll see what input data your model takes and its associated output data. For ResNet50 you’ll see it takes a 224x224 colour image, it’s important that your input image is exactly 224x224 as the model will fail to parse the image if it’s not. The model will also give 2 outputs: the label that matches its highest-confidence prediction and a dictionary of other possible labels with their associated confidence levels.
Now let’s head over to our ViewController.swift file to start making predictions!
Your class should look something like the class below. 2 labels for our prediction and confidence, our input image UIIMageView, our @IBAction function to predict the image when the button is tapped and lastly, our ResNet50 model. Yup, it’s as simple as a one line instantiation to get our model ready for input.
import UIKit
class ViewController: UIViewController {
@IBOutlet weak var inputImage: UIImageView!
@IBOutlet weak var predictionLabel: UILabel!
@IBOutlet weak var confidenceLabel: UILabel!
let model = Resnet50() // instantiates our model
override func viewDidLoad() {
super.viewDidLoad()
}
@IBAction func predictImage(sender: Any) { // this will be called on a button press
}
}
Unfortunately CoreML doesn’t allow UIImages or CGImages to be passed directly into our models so we’ll need to convert our input image into a CVPixelBuffer. Create a new swift file named “ImageProcessor.swift” and copy the following code:
import CoreVideo
struct ImageProcessor {
static func pixelBuffer (forImage image:CGImage) -> CVPixelBuffer? {
let imageWidth = Int(image.width)
let imageHeight = Int(image.height)
let attributes : [NSObject:AnyObject] = [
kCVPixelBufferCGImageCompatibilityKey : true as AnyObject,
kCVPixelBufferCGBitmapContextCompatibilityKey : true as AnyObject]
var buffer: CVPixelBuffer? = nil
CVPixelBufferCreate(kCFAllocatorDefault,
imageWidth,
imageHeight,
kCVPixelFormatType_32ARGB,
attributes as CFDictionary?,
&buffer)
if let pixelBuffer = buffer {
let flags = CVPixelBufferLockFlags(rawValue: 0)
CVPixelBufferLockBaseAddress(pixelBuffer, flags)
let pixelData = CVPixelBufferGetBaseAddress(pixelBuffer)
let rgbColorSpace = CGColorSpaceCreateDeviceRGB();
let context = CGContext(data: pixelData,
width: imageWidth,
height: imageHeight,
bitsPerComponent: 8,
bytesPerRow: CVPixelBufferGetBytesPerRow(pixelBuffer),
space: rgbColorSpace,
bitmapInfo: CGImageAlphaInfo.premultipliedFirst.rawValue)
if let _context = context {
_context.draw(image, in: CGRect.init(x: 0, y: 0, width: imageWidth, height: imageHeight))
} else {
CVPixelBufferUnlockBaseAddress(pixelBuffer, flags);
return nil
}
CVPixelBufferUnlockBaseAddress(pixelBuffer, flags);
return pixelBuffer;
}
return nil
}
}
Don’t worry if this code is overwhelming, this is out of the scope of the tutorial and is merely a way of converting our input image to a format that our ML model will understand.
Now heading back to our view controller, let’s start adding code to our button action so we can start seeing results.
First, add a guard let statement to our input image to ensure we don’t pass a nil value to our model
guard let imageToPredict = image?.image?.cgImage else { return }
Next, let’s use our ImageProcessor we just made to convert our input image into a CVPixelBuffer
let pixelBuffer = ImageProcessor.pixelBuffer(forImage: imageToPredict) {
}
The if let guarantees we only pass the data to the model if the pixelBuffer() function returns a successful conversion.
Next, in the body of our if let, let’s add the line of code we’ve all been waiting for: the actual prediction.
Yeah, that’s really it, one line of code to take in an image, pass it to our model and receive a prediction. Pretty amazing!
We’re not quite done yet though, next we need to take our prediction object and use it to update our UI. Add the following lines of code below the prediction line:
predictionLabel.text = prediction.classLabel
if let confidence = prediction.classLabelProbs[prediction.classLabel] {
let percentage = confidence * 100
confidenceLabel.text = "\(percentage.rounded())%"
} else {
confidenceLabel.text = "Error retrieving confidence"
}
This code updates our label to the models most confident prediction as well as updates the confidence label. At the end of this your button action should look like this:
@IBAction func imageTapped(sender: Any) {
guard let imageToPredict = image?.image?.cgImage else { return }
if let pixelBuffer = ImageProcessor.pixelBuffer(forImage: imageToPredict) {
guard let prediction = try? model.prediction(image: pixelBuffer) else { return }
predictionLabel.text = prediction.classLabel
if let confidence = prediction.classLabelProbs[prediction.classLabel] {
let percentage = confidence * 100
confidenceLabel.text = "\(percentage.rounded())%"
} else {
confidenceLabel.text = "Error retrieving confidence"
}
}
}
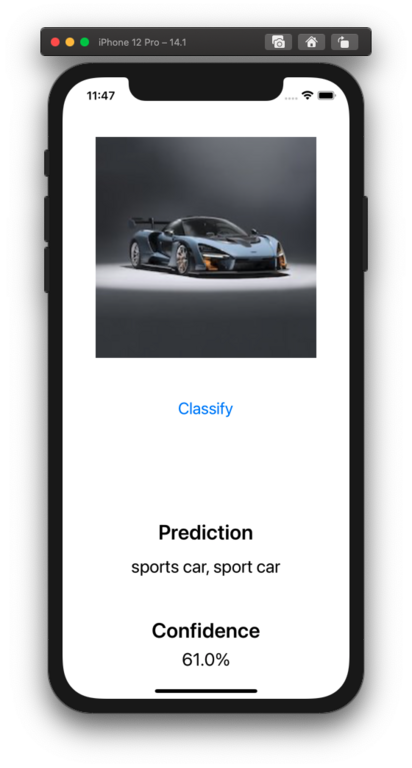
And believe it or not, that’s it! We’ve taken a machine learning model, passed it an input image, got a prediction, and updated our UI accordingly. Make sure your UIImageView has a default image and run your app, your simulator should display something similar:
Note: running your app with a default image in the UIImageView is merely for simplicity, if you want to go the extra mile by adding an image picker or camera input, go for it! Just remember to include some logic to downsize your input image to 224x224.
What happened to training?
Earlier we discussed the idea of training the “black box” and how well we trained it determined how accurate our results would be. In the case of ResNet50, it is a model that has already been thoroughly trained on huge datasets so that you don’t have to, hence the easy plug and play code we just went through, however ResNet50 is a very generic image classifying model as in it’ll identify generic dominant objects. As we saw in our example the model identified our sports car, but didn’t specifically identify it as a McLaren. If your use case is identifying different cars makes and models, for example, you would have to train your own model and feed it in datasets defining each vehicle's make and model. Apple also makes this process very simple with CreateML: a drag and drop interface for training your own ML models. With CreateML you simply drag and drop your training, validation and test image datasets and CreateML will train and create a model for you that you can use, just like the ResNet50 model we used.
Summary
In this tutorial we touched on CoreML, Apple’s machining learning framework for iOS, tvOS and MacOS by building a simple image classifying app. We learnt that while machine learning is a complex process, the end result can be viewed simply as some function that takes input and gives a corresponding output. We used ResNet50 to determine dominant objects in our UIImage by converting the image to a pixel buffer and feeding it into the model. We also learnt that the CoreML framework is very simple to use with only a few lines of code and the majority of our code being the image conversion!
Image classification is only the tip of the iceberg when it comes to using CoreML in your app, with other use cases involving speech recognition, style transfer, text classification and much more. Hopefully you learned something in this tutorial and this just the start of building AI into your apps!
Tell us about your project
We believe that something amazing can come from combining your vision with our expertise.